import matplotlib.pyplot as plt # 시각적 그래프를 그리기 위한 matplotlib의 pyplot 모듈을 임포트함
print("=== [실습 1-3] 오컴의 면도날: 모델 복잡도와 과적합의 딜레마 ===")
# ---------------------------------------------------------
# 1. 훈련용 데이터(기출문제) 생성 구역
# ---------------------------------------------------------
np.random.seed(0) # 코드를 다시 실행해도 똑같은 난수(노이즈)가 발생하도록 시드를 0으로 고정함
# 0부터 10까지의 구간을 15개의 일정한 간격으로 쪼개어 입력 데이터(X축: 자극)를 생성함
x_train = np.linspace(0, 10, 15)
# 피험자 뇌의 '진짜 원리(정답)'를 부드러운 사인(sin) 곡선이라고 가정하고 계산함
true_trend = np.sin(x_train)
# 진짜 원리에 무작위 노이즈(평균 0, 표준편차 0.3)를 더해 피험자의 우연한 실수(재채기 등)가 반영된 실제 관측 데이터를 만듦
y_train = true_trend + np.random.normal(0, 0.3, 15)
# ---------------------------------------------------------
# 2. 두 가지 모델 피팅 시도 구역 (단순 모델 vs 과적합 모델)
# ---------------------------------------------------------
# [단순한 모델]: 3차 방정식(파라미터 4개)으로 데이터의 거시적 흐름만 부드럽게 따라가도록 학습(피팅)함
simple_model_params = np.polyfit(x_train, y_train, 3)
# 도출된 파라미터를 사용해 X를 넣으면 예측값을 뱉어내는 수학 함수 객체로 변환함
simple_model_func = np.poly1d(simple_model_params)
# [과적합 모델]: 14차 방정식(파라미터 15개)으로 15개의 데이터를 강제로 모두 지나가도록 학습(피팅)함
overfitted_model_params = np.polyfit(x_train, y_train, 14)
# 15개의 파라미터를 가져 극도로 구불구불한 궤적을 뱉어내는 괴물 같은 예측 함수 객체를 생성함.
overfitted_model_func = np.poly1d(overfitted_model_params)
# ---------------------------------------------------------
# 3. 훈련 데이터에 대한 SSE(오차 제곱합) 채점 구역
# ---------------------------------------------------------
# 실제 데이터(y_train)에서 단순 모델의 예측값을 뺀 뒤, 모조리 제곱하여 더함(SSE 벌점 계산)
sse_simple = np.sum((y_train - simple_model_func(x_train))**2)
# 실제 데이터에서 과적합 모델의 예측값을 뺀 뒤, 모조리 제곱하여 더함
sse_overfit = np.sum((y_train - overfitted_model_func(x_train))**2)
# 채점 결과를 소수점 둘째 자리(.2f)까지 깔끔하게 텍스트로 출력함
print(f"-> [단순 모델]의 훈련 SSE: {sse_simple:.2f} (적당한 오차 존재)")
print(f"-> [과적합 모델]의 훈련 SSE: {sse_overfit:.2f} (오차가 0에 수렴! 기출문제 완벽 암기!)")
print("\n-> 통찰: 과적합 모델은 훈련 SSE를 0으로 만들었지만, 15개나 되는 파라미터를 동원해 피험자의 우연한 노이즈까지 수학적 진리로 착각해버린 상태임. 새로운 데이터가 들어오면 예측력이 완전히 박살남.\n")
# ---------------------------------------------------------
# 4. 그래프 시각화 구역(과적합을 눈으로 직접 확인하기)
# ---------------------------------------------------------
# 모델의 예측곡선을 뚝뚝 끊기지 않고 부드럽게 그리기 위해, 0부터 10 구간을 100개로 잘게 쪼갠 X축 렌더링용 데이터를 새로 만듦
x_dense = np.linspace(0, 10, 100)
# 가로 10인치, 세로 6인치 크기의 넉넉한 도화지(그래프 창)를 준비함
plt.figure(figsize=(10, 6))
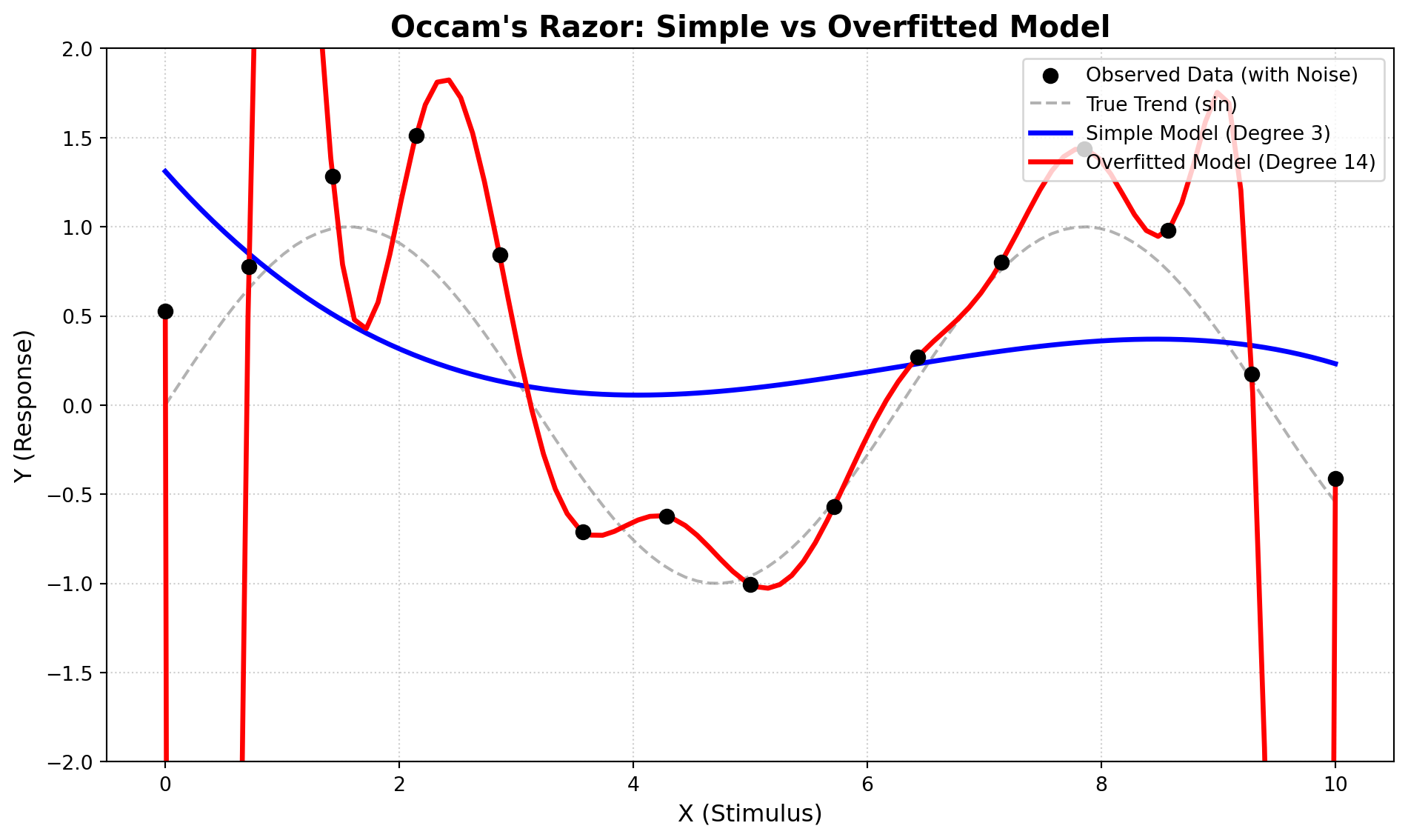
# [1] 피험자가 남긴 실제 데이터(노이즈 포함)를 검은색 점(scatter)으로 찍음. zorder=5로 설정해 선들보다 맨 위로 튀어나오게 띄움
plt.scatter(x_train, y_train, color='black', s=50, label='Observed Data (with Noise)', zorder=5)
# [2] 자연의 진짜 법칙인 순수 사인(sin) 곡선을 눈에 덜 띄는 회색 점선으로 부드럽게 밑그림으로 깔아줌
plt.plot(x_dense, np.sin(x_dense), color='gray', linestyle='--', label='True Trend (sin)', alpha=0.6)
# [3] 오컴의 면도날 원칙을 지킨 단순한 모델의 예측궤적을 굵은 파란색 선으로 그림(결과적으로 과소적합[underfitting] 모델의 예측궤적을 보여줌)
plt.plot(x_dense, simple_model_func(x_dense), color='blue', linewidth=2.5, label='Simple Model (Degree 3)')
# [4] 오차(SSE)를 0으로 만들려다 무의미한 노이즈까지 모조리 외워버린 과적합 모델의 예측궤적을 굵은 빨간색 지그재그 선으로 그림
plt.plot(x_dense, overfitted_model_func(x_dense), color='red', linewidth=2.5, label='Overfitted Model (Degree 14)')
# 그래프 최상단의 제목을 굵은 폰트(bold)와 15 사이즈로 설정함
plt.title("Occam's Razor: Simple vs Overfitted Model", fontsize=15, fontweight='bold')
# X축과 Y축의 직관적인 이름표를 각각 달아줌
plt.xlabel("X (Stimulus)", fontsize=12)
plt.ylabel("Y (Response)", fontsize=12)
# 빨간 선이 과적합으로 인해 화면 밖으로 뚫고 나가는 것을 막기 위해, Y축의 시각적 출력 범위를 -2부터 2까지로 억제함
plt.ylim(-2, 2)
# 각 선이 무엇을 의미하는지 알려주는 범례(Legend)를 그래프의 오른쪽 위(upper right) 구석에 배치함
plt.legend(loc='upper right', fontsize=10)
# 눈금을 알아보기 쉽게 배경에 점선 형태의 그리드(격자)를 은은하게 깔아줌
plt.grid(True, linestyle=':', alpha=0.6)
# 여러 그래픽 요소나 글자가 서로 겹치지 않게 여백을 깔끔하게 자동 조절함
plt.tight_layout()
# 최종적으로 렌더링이 완성된 그래프 창을 모니터 화면에 띄움
plt.show()