import matplotlib.pyplot as plt # 도화지에 그림을 그리는 시각화 라이브러리를 plt라는 약칭으로 불러옴.
# X축에 뿌려줄 데이터 100개 생성( -5부터 5 사이를 균일하게 100조각으로 자름 )
x_val = np.linspace(-5, 5, 100) # -5.0부터 5.0 구간을 100개의 점으로 균일하게 나눈 넘파이 배열을 생성해 x_val 변수에 저장함.
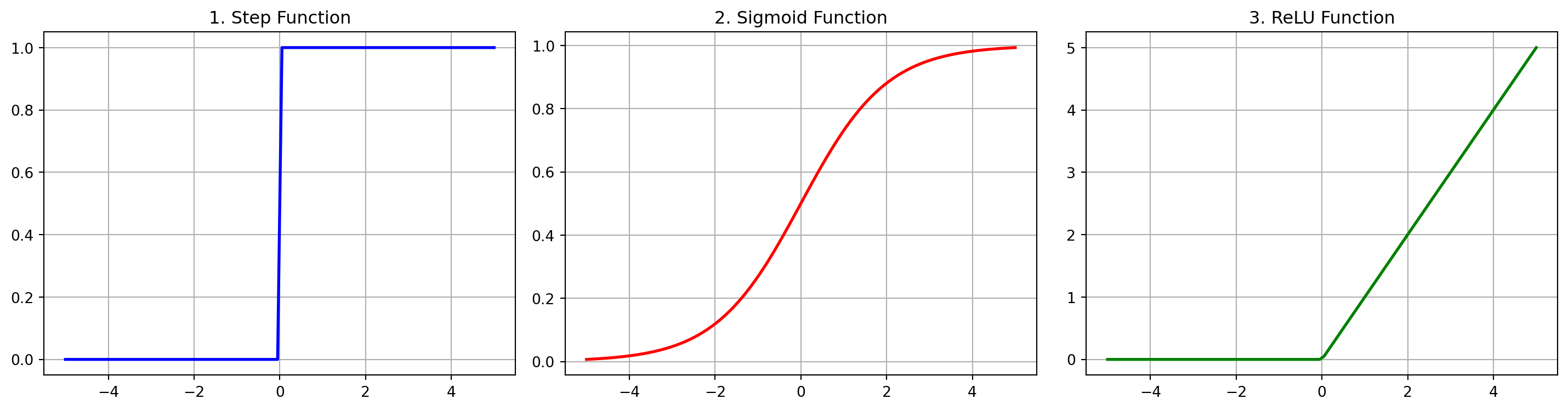
# 1. 똑딱이 스위치(계단 함수)
def step_function(x): # x라는 입력을 받아서 계단 함수 결과를 반환하는 사용자 정의 함수를 선언함.
# 입력된 x가 0을 넘기면 True(1), 못 넘기면 False(0)가 되는 배열을 만들어 정수형(int)으로 반환함.
return np.array(x > 0, dtype=int) # 불리언 연산(x > 0)의 결과를 정수형(0 또는 1) 배열로 변환하여 그대로 반환함.
# 2. 다이얼 조광기(시그모이드 함수)
def sigmoid(x): # x라는 입력을 받아서 시그모이드 함수 곡선 결과를 반환하는 사용자 정의 함수를 선언함.
# 부드러운 S자 곡선을 그리는 시그모이드 공식: 1 /(1 + e^(-x)) 를 파이썬 코드로 구현함.
return 1 /(1 + np.exp(-x)) # 자연 상수 e의 -x승을 계산하여 분모에 더한 후 1을 나누어 결과값을 반환함.
# 3. 딥러닝 수도꼭지(렐루 함수)
def relu(x): # x라는 입력을 받아서 렐루 함수 결과를 반환하는 사용자 정의 함수를 선언함.
# 입력된 수많은 x값 중, 0보다 큰 양수들은 자기 자신 그대로 살리고, 음수들은 모조리 0으로 뭉개버림.
return np.maximum(0, x) # x 원소들과 숫자 0을 비교하여 0보다 작은 음수들을 모두 0으로 덮어씌워 반환함.
# 1줄에 3칸이 나뉘어진 넓은 도화지(가로 15, 세로 4 비율)를 준비함. fig는 캔버스 전체, axes는 3개의 방을 의미함.
fig, axes = plt.subplots(1, 3, figsize=(15, 4)) # 1x3 그리드의 서브플롯 영역을 만들고, 전체 크기를 가로 15인치, 세로 4인치로 지정함.
# 첫 번째 방(axes[0])에 파란색으로 계단 함수 펜선을 긋고(plot), 모눈종이(grid)와 제목을 단다.
axes[0].plot(x_val, step_function(x_val), color='blue', linewidth=2) # x_val을 바탕으로 계단 함수 결과값을 파란색 굵은 선(굵기 2)으로 그림.
axes[0].set_title("1. Step Function") # 첫 번째 그래프 상단에 '1. Step Function'이라는 문자열을 제목으로 달아줌.
axes[0].grid(True) # 첫 번째 그래프의 배경에 눈금을 읽기 쉽게 격자 무늬(모눈종이)를 활성화함.
# 두 번째 방(axes[1])에 빨간색으로 시그모이드 함수 펜선을 긋고 세팅함.
axes[1].plot(x_val, sigmoid(x_val), color='red', linewidth=2) # x_val을 바탕으로 시그모이드 결과를 빨간색 굵은 선(굵기 2)으로 그림.
axes[1].set_title("2. Sigmoid Function") # 두 번째 그래프 상단에 '2. Sigmoid Function'이라는 문자열을 제목으로 달아줌.
axes[1].grid(True) # 두 번째 그래프의 배경에 눈금을 읽기 쉽게 격자 무늬(모눈종이)를 활성화함.
# 세 번째 방(axes[2])에 초록색으로 렐루 함수 펜선을 긋고 세팅함.
axes[2].plot(x_val, relu(x_val), color='green', linewidth=2) # x_val을 바탕으로 렐루 함수 결과를 초록색 굵은 선(굵기 2)으로 그림.
axes[2].set_title("3. ReLU Function") # 세 번째 그래프 상단에 '3. ReLU Function'이라는 문자열을 제목으로 달아줌.
axes[2].grid(True) # 세 번째 그래프의 배경에 눈금을 읽기 쉽게 격자 무늬(모눈종이)를 활성화함.
# 3개의 그래프가 서로 영역을 침범하지 않고 깔끔하게 보이도록 여백을 컴퓨터가 알아서 자동 조정해 줌.
plt.tight_layout() # 서브플롯 간의 간격을 조절하여 글자나 축 번호가 서로 겹치지 않게 여백을 최적화함.
plt.show() # 지금까지 설정한 모든 시각화 결과물들을 렌더링하여 사용자 화면에 실제로 띄워 보여줌.